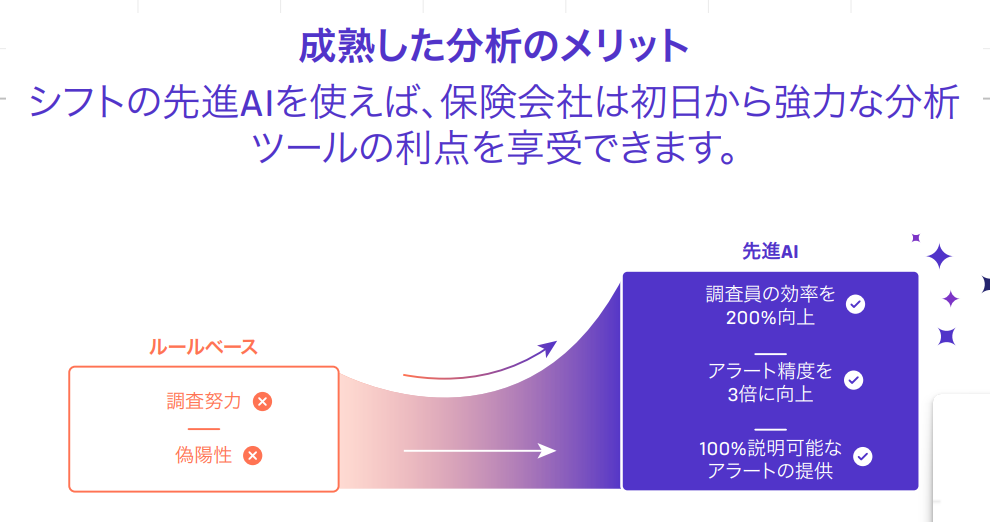
人工知能 (AI) と生成人工知能 (GenAI) の活用が浸透することで保険の重要なプロセスが改善されており、継続的に保険業界を魅了しています。その一方で、急速に変化する状況を乗り切り、これらのイノベーションをどのように導入すれば最良の結果が得られるかについて最善の決断を下すことは、非常に難しくなっています。
前回のレポート保険業界における AI の現状では、保険に特化したいくつかのユースケースに適用した 6 つの異なる大規模言語モデル (LLM) のパフォーマンスを調査しました。シフトのデータサイエンティストと研究者は、事前に設定された一連のタスクに対する相対的なパフォーマンスを比較するだけでなく、テストされた各 LLMに関するコストとパフォーマンスの比較を試みました。
Vol.II では、新たに 8 つの LLM をテストし、前回のレポートに登場した 2 つの LLM は外しました。新たにテストされたモデルは、Llama3-8b、Llama3-70b、GPT4o、Command r、Command r+、Claude3 Opus、Claude3 Sonnet、Claude3 Haiku です。前回のレポートに掲載した Llama2 モデルを比較対象から外し、Llama3 モデルに変更しました。Llama3 は、現在利用可能な LLM の中でも代表的な最先端のモデルです。
さらに、このレポートでは各モデルで生成された F1 スコアをハイライトした新しい表を追加しています。このレポートでは、F1 スコアは特定のユースケースを表わす 2 つの軸 ( 例: フランス語の歯科請求書) とこれに関連する個々のフィールドに対するカバー率と精度をまとめています。このアプローチにより、ユースケースごとに 1 つのパフォーマンス指標を生成できるだけでなく、10 万もの文書の分析に関連するコストを含んだ総合的なスコアも生成できます。F1 スコアの生成に使用した式: 2 x Cov x Acc / (Cov + Acc)
本レポートの作成にご協力いただいたシフトのデータサイエンス チームと研究チームに皆様に感謝いたします。
レポートをこちらからダウンロードする